YY's Random Walks: Measuring disruption and Claude Scholar plugin
2026-04-04
Two things this time: a new paper on measuring scientific disruption, and a Claude Code plugin for academic workflows.
Measuring disruption#
Our paper “Uncovering simultaneous breakthroughs with a robust measure of disruptiveness” just came out in Science Advances. The disruption index has an elegant idea: if a paper is truly disruptive, future work cites it but stops citing its references. But because it relies on local citation topology, simultaneous discoveries break it. When multiple papers make the same breakthrough, they cite each other, and those mutual citations make each paper look “consolidating” rather than disruptive.
The Higgs mechanism is a perfect example. Three independent teams proposed it in 1964, yet the disruption index ranks one paper near the top and the others at the very bottom. We kept finding this pattern across reverse transcriptase, the charm quark, asymptotic freedom, and other famous simultaneous discoveries.
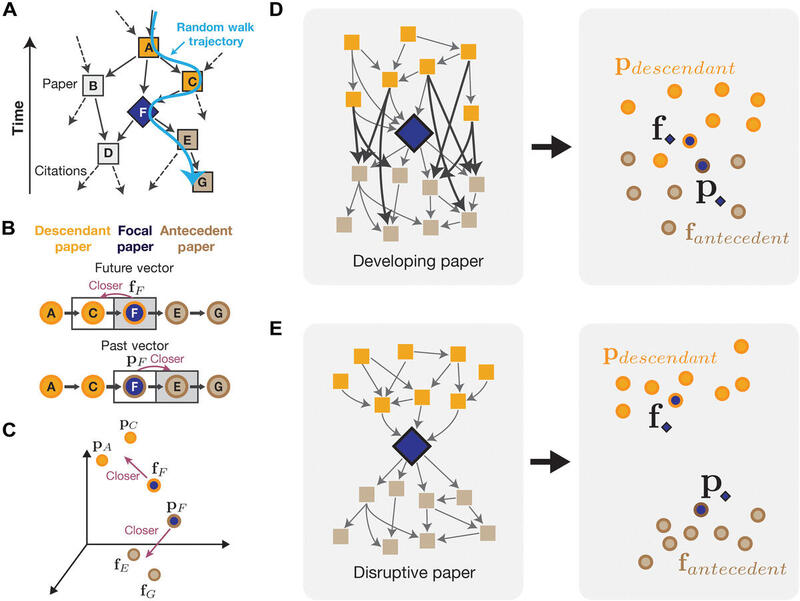
We introduce an embedding-based measure that resolves this. Each paper gets two vectors, one for its prior context and one for its future context, and the distance between them captures how much a paper redirected the field. Nobel Prize-winning and milestone papers consistently score high on our measure.
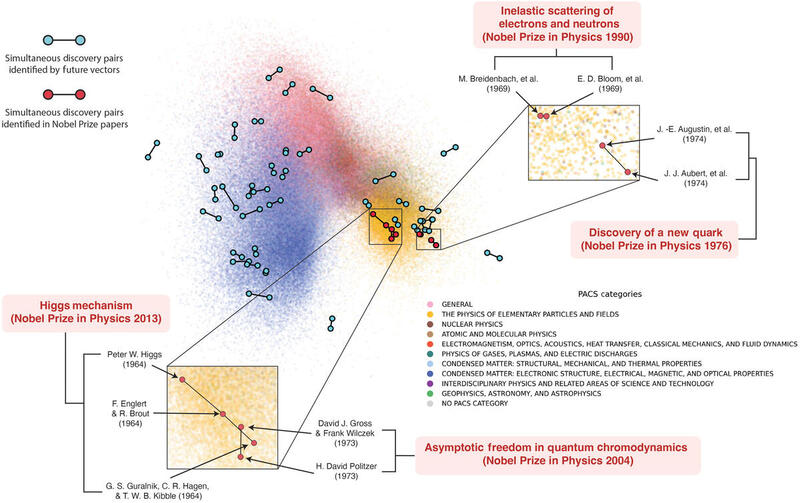
But a really interesting thing is that the vectors themselves let us discover simultaneous breakthroughs. The future vectors roughly capture how a paper is used in subsequent literature. If two papers that came out around the same time have very similar future vectors and high disruptiveness scores, they are likely simultaneous discoveries. If they cite each other, the disruption index would tank, but our measure still sees them as important. By combining these signals, we can systematically identify simultaneous disruption events across science. Munjung Kim’s blog post walks through the study in detail. See also her posts on Bluesky and LinkedIn.
Claude scholar plugin#
I’ve been building Claude Code skills for academic workflows and packaged them as a plugin called Claude Scholar.
- claude-scholar (on GitHub)
The key design principle is that these skills don’t try to do the thinking, researching, or writing for you. For those tasks, there’s a whole can of worms (ethical, pedagogical, reliability), and even setting those aside, there’s a vast space of how to prompt and use AI. It’s counterproductive to try to consolidate that into a fixed skill when the underlying models and systems keep advancing rapidly. For this type of fluid tasks, you can very easily over-engineer and mis-step.
Instead, the plugin focuses on concrete, verifiable tasks that are tedious to do by hand but where correctness is easy to check: fetching arXiv metadata, grabbing a BibTeX entry from a DOI, querying OpenAlex’s 240M+ scholarly works, verifying each step of a math derivation with SymPy, checking your references against databases, auditing figures for colorblind risk and resolution issues, walking through a checklist for arXiv submission. These are the kinds of tasks that don’t require judgment calls—they just need to get done right.
The skills are also composable: each does one thing and can be chained by other skills or agents. For instance, the skill for presubmission checks launches multiple agents in parallel to verify references, audit figures, check LaTeX formatting, and review front matter, then presents a unified report. You should also be able to easily build your own skills on top of these building blocks.
If you use Claude Code for academic work, give it a try! More details on my wiki post.
That’s it for now. More soon!
yy